Introduction
In this project, I explored how to use machine learning algorithms to classify tweets as disaster or non-disaster related. My goal was to build a model that could accurately predict whether a tweet is related to a disaster or not. I used a dataset of tweets that had been labeled as disaster or non-disaster to train my model. The dataset contained a variety of tweets that were related to different types of disasters such as earthquakes, floods, and fires. By the end of this project, I gained a better understanding of how NLP can be used to classify tweets and how machine learning algorithms can be used to build predictive models.
Natural language is a broad term but you can consider it to cover any of the following:
* Text (such as that contained in an email, blog post, book, Tweet)
* Speech (a conversation you have with a doctor, voice commands you give to a smart speaker)
Steps:
Text -> turn into numbers -> build a model -> train the model to find patterns -> use patterns (make predictions)
* Downloading a text dataset
* Visualizing text data
* Converting text into numbers using tokenization
* Turning our tokenized text into an embedding
* Modelling a text dataset
* Starting with a baseline (TF-IDF)
* Building several deep learning text models
* Dense, LSTM, GRU, Conv1D, Transfer learning
* Comparing the performance of each our models
* Combining our models into an ensemble
* Saving and loading a trained model
* Find the most wrong predictions
Downloading a text dataset
I started by downloading a text dataset [Real or Not?](https://www.kaggle.com/c/nlp-getting-started/data) from Kaggle which contains text-based Tweets about natural disasters.
The Real Tweets are actually about disasters, for example:
Modelling Experiments
* Model 0: Naive Bayes (baseline)
* Model 1: Feed-forward neural network (dense model)
* Model 2: LSTM model
* Model 3: GRU model
* Model 4: Bidirectional-LSTM model
* Model 5: 1D Convolutional Neural Network
* Model 6: TensorFlow Hub Pretrained Feature Extractor
* Model 7: Same as model 6 with 10% of training data
Model 0 is the simplest to acquire a baseline which we’ll expect each other of the other deeper models to beat.
Each experiment will go through the following steps:
* Construct the model
* Train the model
* Make predictions with the model
* Track prediction evaluation metrics for later comparison
Converting text into numbers
In NLP, there are two main concepts for turning text into numbers:
Tokenization- A straight mapping from word or character or sub-word to a numerical value. There are three main levels of tokenization:
- Using word-level tokenization with the sentence “I love TensorFlow” might result in “I” being `0`, “love” being `1` and “TensorFlow” being `2`. In this case, every word in a sequence considered a single **token**.
- Character-level tokenization, such as converting the letters A-Z to values `1-26`. In this case, every character in a sequence considered a single token .
- Sub-word tokenization is in between word-level and character-level tokenization. It involves breaking individual words into smaller parts and then converting those smaller parts into numbers. For example, “my favorite food is pineapple pizza” might become “my, fav, avour, rite, fo, oo, od, is, pin, ine, app, le, pizza”. After doing this, these sub-words would then be mapped to a numerical value. In this case, every word could be considered multiple tokens.
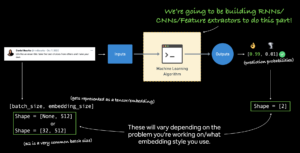
Embeddings– An embedding is a representation of natural language which can be learned. Representation comes in the form of a feature vector. For example, the word “dance” could be represented by the 5-dimensional vector `[-0.8547, 0.4559, -0.3332, 0.9877, 0.1112]`. It’s important to note here, the size of the feature vector is tunable. There are two ways to use embeddings:
- Create custom embedding – Once your text has been turned into numbers (required for an embedding), they can put through an embedding layer (such as [`tf.keras.layers.Embedding`] and an embedding representation will be learned during model training.
- Reuse a pre-learned embedding – Many pre-trained embeddings exist online. These pre-trained embeddings have often been learned on large corpuses of text (such as all of Wikipedia) and thus have a good underlying representation of natural language.
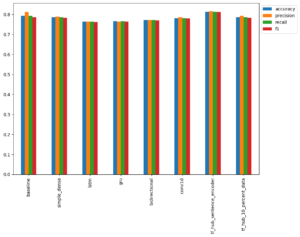
Comparing the performance of each of our models
Based on only F1 score:
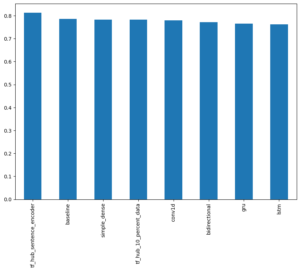
The baseline outperforms most of the models besides the model with the pretrained universal sentence encoder this shows that not always does a deep neural outperforms simple models, at time simple is better. Other models such as lstm or conv1d can be improved by stacking more layers to improve performance.
Most wrong Predictions:
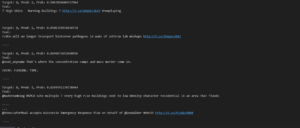
On the second example of most wrong prediction it understandable as the most saw bioterror and sounded alarms. The models won’t understand the full context as we humans would.
In some cases the data label is straight up wrong and we updated these labels .
In conclusion this project was fun and at the same time hard to grasp , i learnt a lot .Here is github project Link
I am a beginner myself , we can link up and help each other. I can help you with what I know and vice versa.